Project - Image Classifier
- NIRAJ KUMAR
- Nov 30, 2022
- 6 min read

Problem Statement:To build an Image classifier for wild animals : Classify the images into six classes cheetah, fox, lion, hyena, tiger, wolf.

I have referenced the [1] PyTorch tutorial code for building this image classifier and modified the Hyper-parameters to get the better accuracy and code to split the data and create dataset is used from this [2] link. I have used sklearn machine learning algorithms for Accuracy and Training time comparison.
CNN Architecture [15]
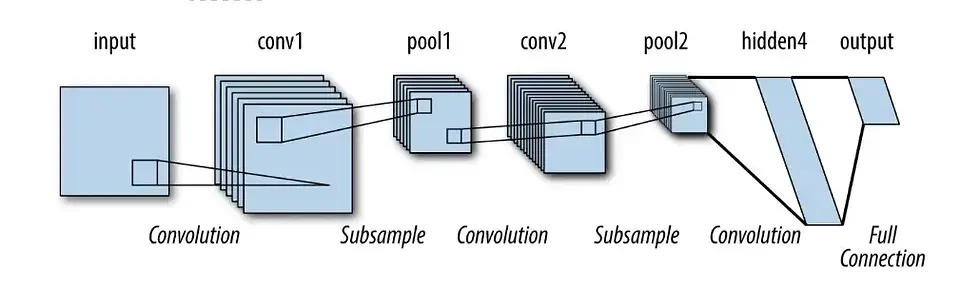
Convolutional Layer: In this layer the convolutional operations are performed by all the neurons in the layer for the input data.
Pooling Layer: I have used AdaptiveAvgPool2d for pooling layer which helps in reducing the input size.
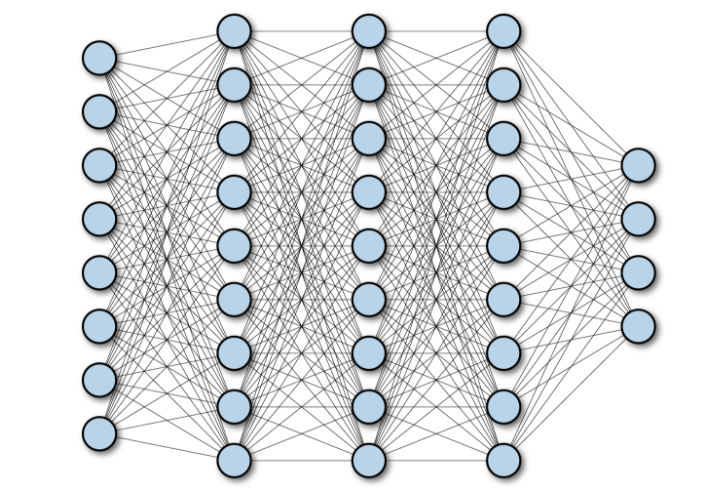
Fully Connected Layer: As the diagram depicted below the fully connected layer connects all neurons in the input and output of all the layers. The last layer which has output of 6 units which is same as number of classes.
Code:
Loading Dataset : Mounting google drive as my data is stored in drive and navigating to that folder

Getting details of dataset size and number of images in each folders. I have used the images having resolution of 512 for all the classes.
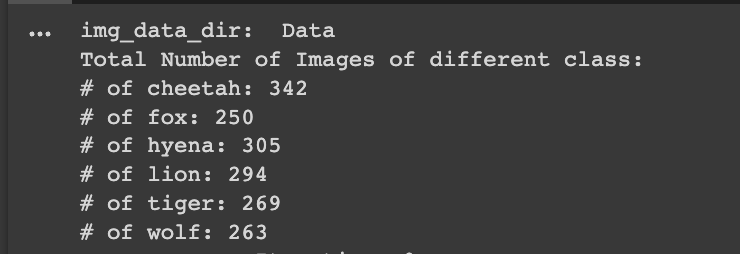
Dataset Information : Number of images in each classes.
Splitting the Dataset into Training and Validation dataset with split ratio of 80:20.

The input is resized to 300,300 and applied Data Augmentation to check the Accuracy of the model for both the Augmented data and non augmented dataset. The Augmentation parameters can be passed in the AugmentationList to transform the dataset images.
Custom code provides user an option to set parameters batchSize, learningRate, select optimizer either "SGD" or "ADAM", number of epochs and pass it to train_model function.
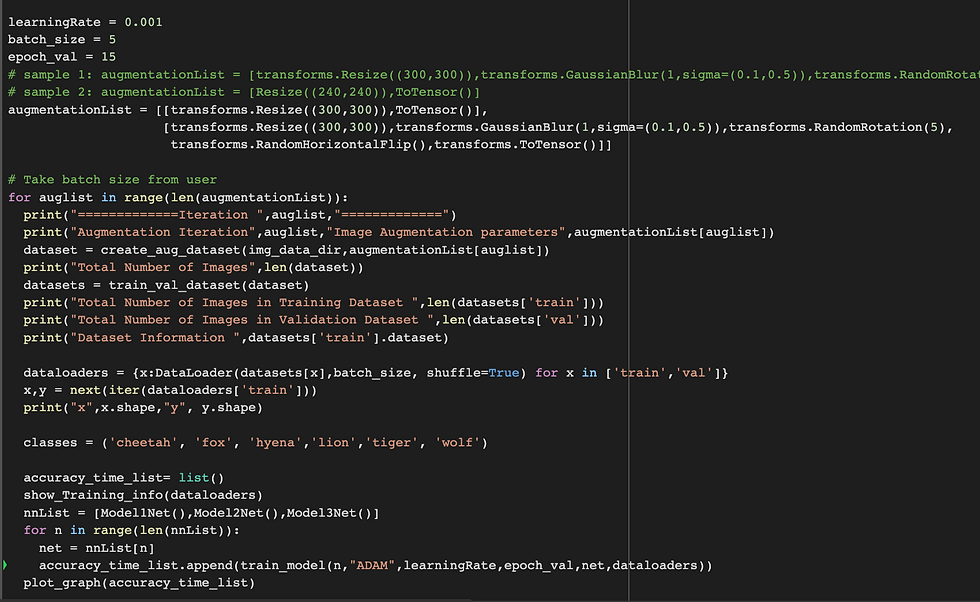
Image Augmentation: AugmentationList passed as a parameter create_aug_dataset() to apply augmentation like resize, horizontal flip on the images.
[[transforms.Resize((300,300)),ToTensor()],
[transforms.Resize((300,300)),transforms.GaussianBlur(1,sigma=(0.1,0.5)),transforms.RandomRotation(5),
transforms.RandomHorizontalFlip(),transforms.ToTensor()]]CNN Model: The models hyper-parameters have been changed to improve the accuracy. In the initial iteration the accuracy was around 22% from model 0 and model 1 &
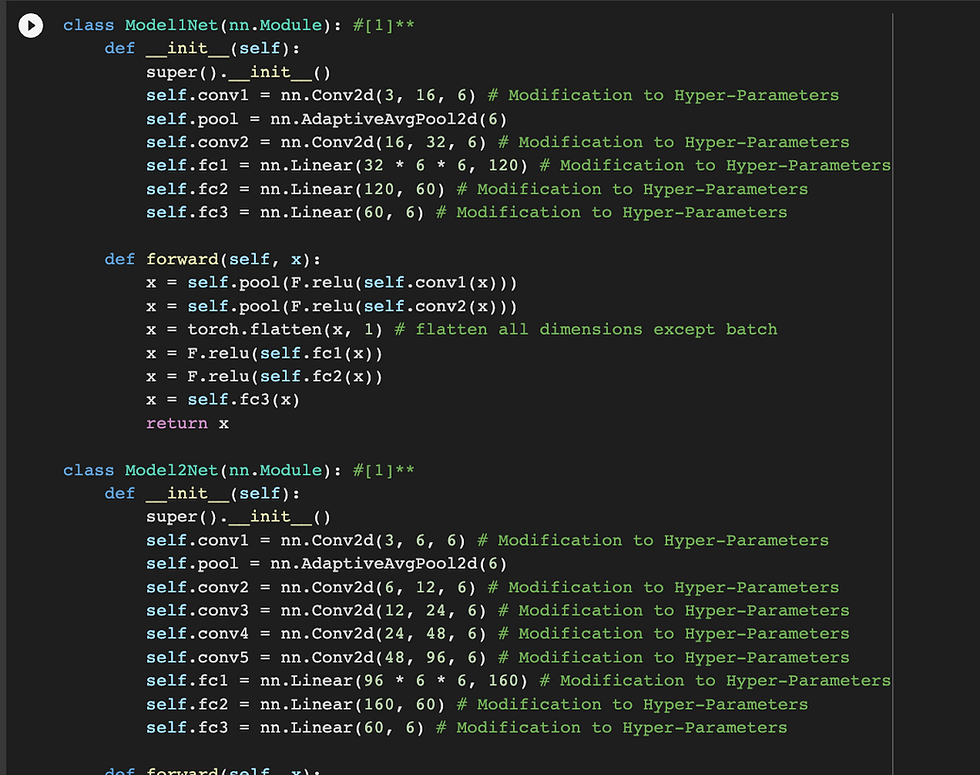
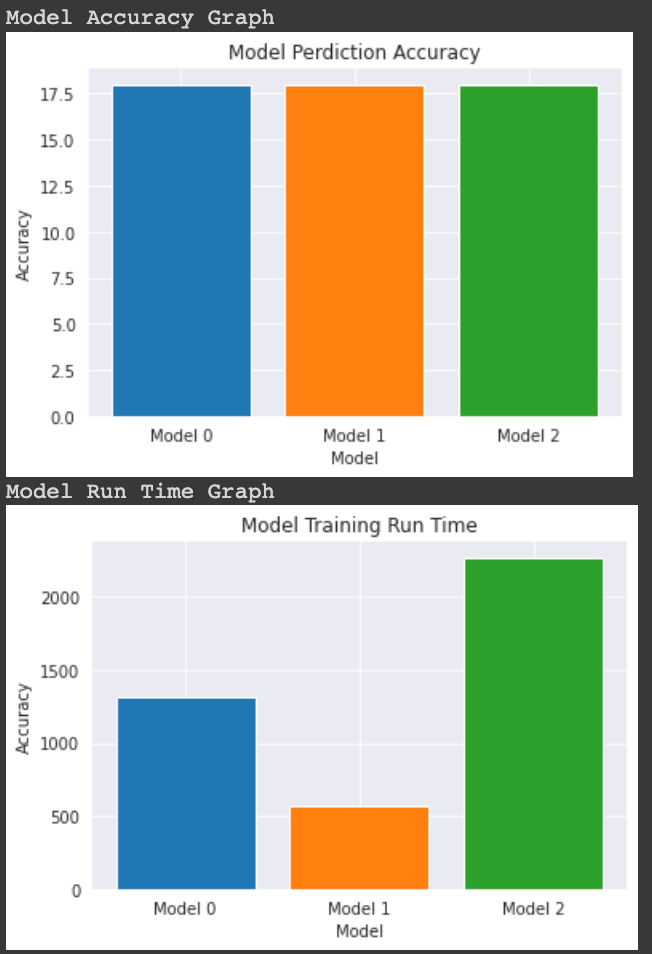
2 performed very poorly. The hyper parameters were modified to get accuracy till 45% from Model 0 and Model 1 & 2 achieved accuracy of ~22% with epoch value of 15.
Loss function and optimizer: CrossEntropyLoss is used in this code for all the models. I have used ADAM optimizer and learning rate of 0.01. We can either use "SGD" or "ADAM" as parameter to use the respective optimizer in train_model() function along with learning rate like (0.001).
Training Model: Train the model on the training dataset. The training time of all three models is calculated and a class accuracy and training time graph is created for the same.

Output with different hyper parameters changes
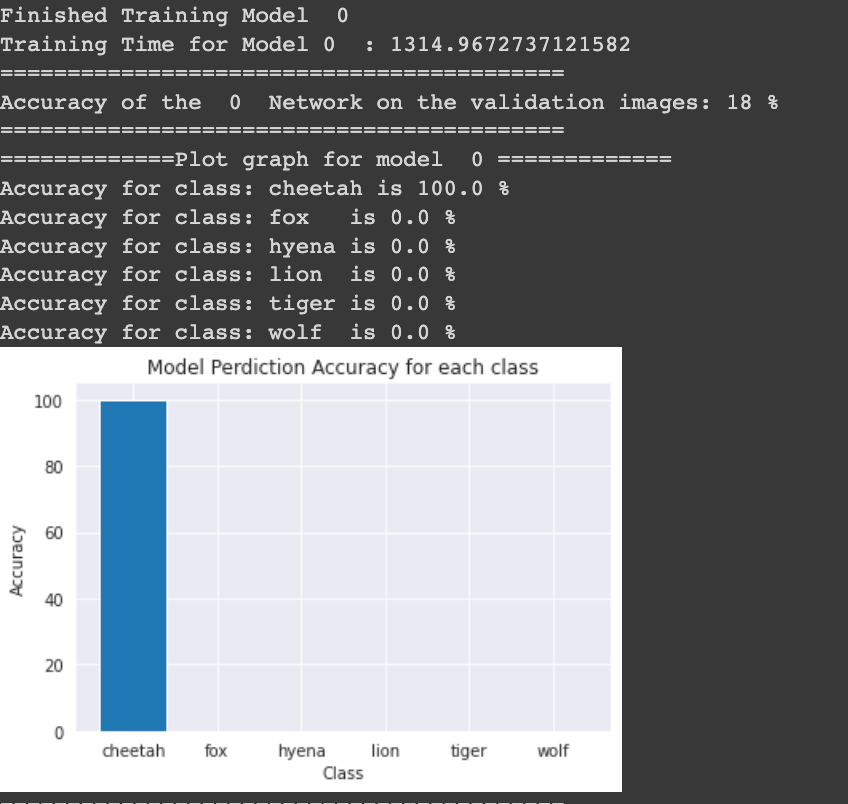
Initial Output having accuracy of 18% from Model 0
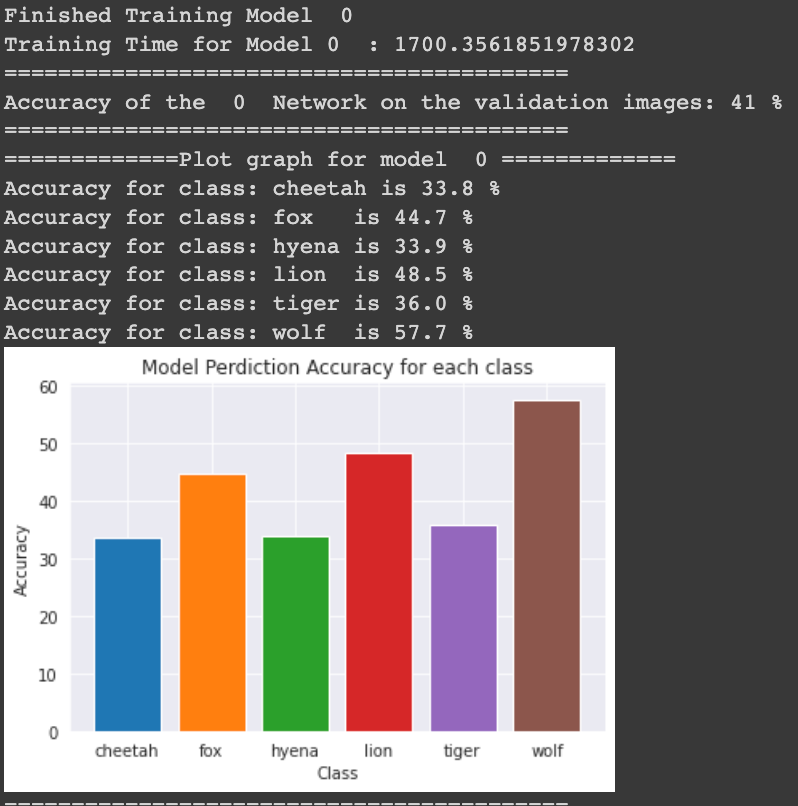

Increased Accuracy to 41% after Tuning the Hyper parameters and epoch value
Increased Accuracy to 45% after Tuning the Hyper parameters and epoch value is set to 15
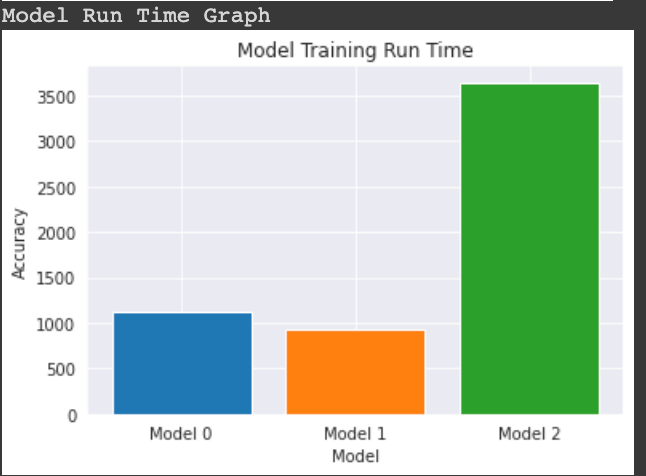
Comparison of accuracy and training run time for all the three CNN model.
Accuracy graph:

Training Time graph:
Machine Learning Algorithm: Let's talk about how the machine learning on the same dataset. I have used five Machine Learning Algorithms like RandomForestClassifier,
SVM, KNN, Gaussian Naive Bayes and Decision tree from SKLearn Library. These algorithms didn't out perform the deep learning model in case of this image dataset.
The average accuracy was around 15%-22% in all these algorithms.
Dataset: The machine learning algorithm does not support 4d array so we had to reshape the dataset to 2d array.

Lets talk about each algorithms and check the code implementation and their performance and training time graph.
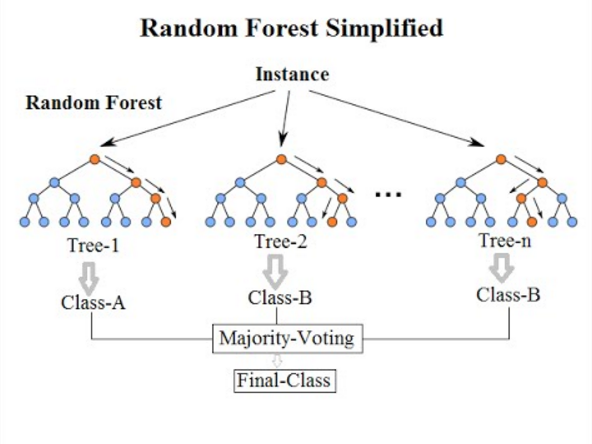
RandomForestClassifier[7,8]: Random forest classifier is a supervised learning method where each image is labeled against it's respective class that image belongs to. Random forest classifier uses decision tree of having randomly selected subset of data from the training data set. It then gathers the decision from all the decision trees to create the final prediction.
Random Forest Classifier generally performs better than decision tree.
Code: Parameters used for RandomForestClassifier n_estimators = 20, max_depth = 8, random_state = 2
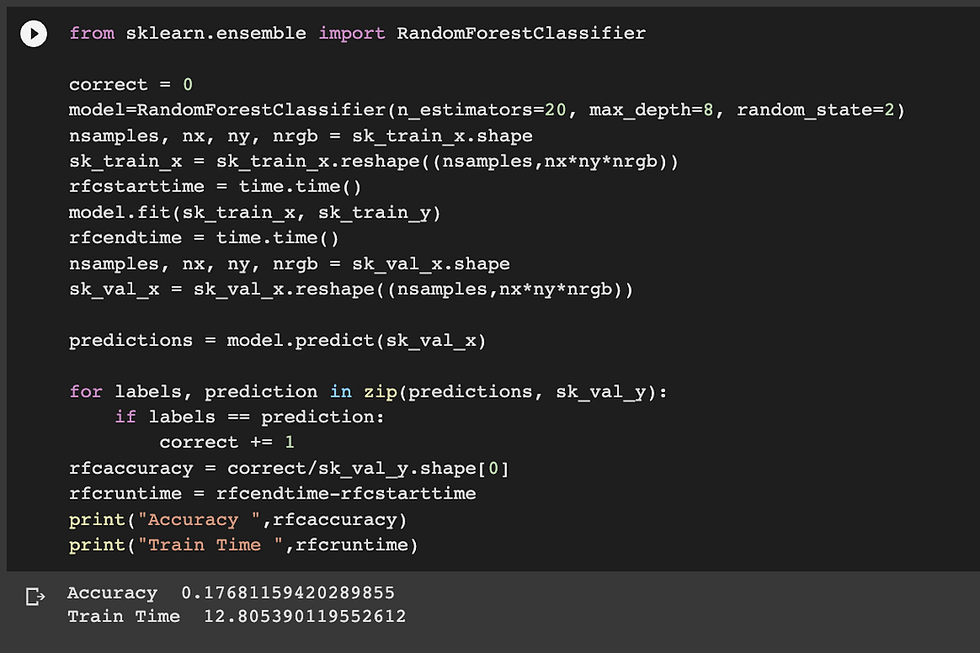
Accuracy: 17.68%
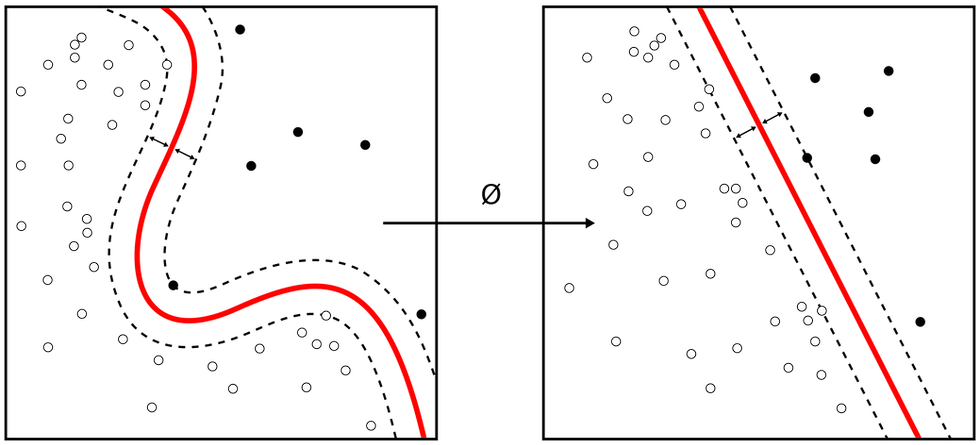
SVM[10]: Support Vector Machine works by finding a hyperplane in an N-dimensional space(N-the number of features) that distinctly classifies the data points and maximize the margin the closest point are considered as support vector from Hyperplane - the red line as depicted in the diagram below and rest all the points are discarded. The Hyper plane which has maximum margin is selected.
Code: Default parameters were used here.
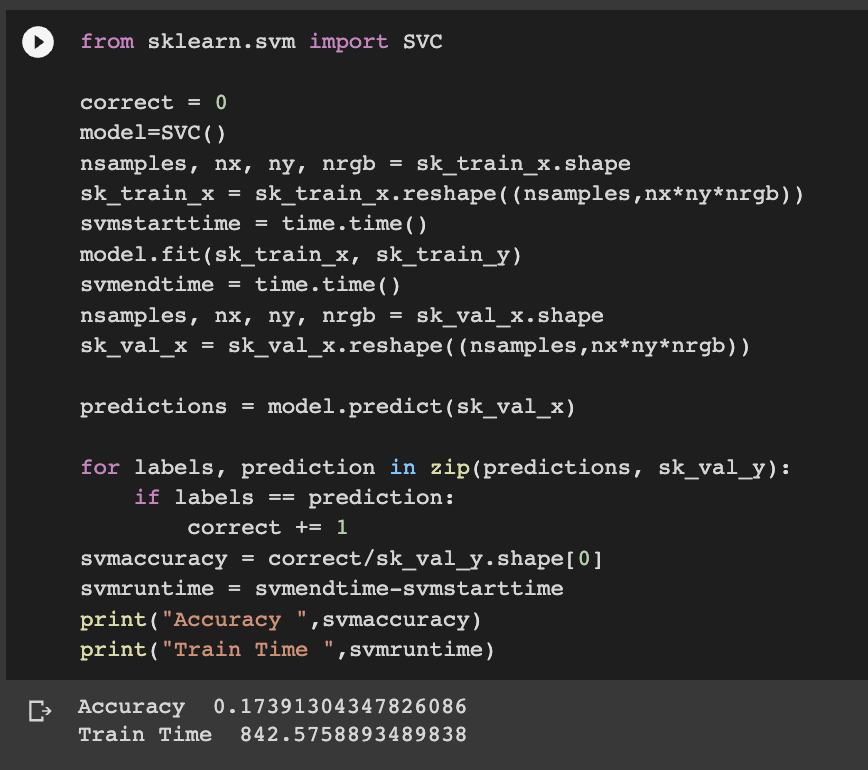
Accuracy: 17.39%
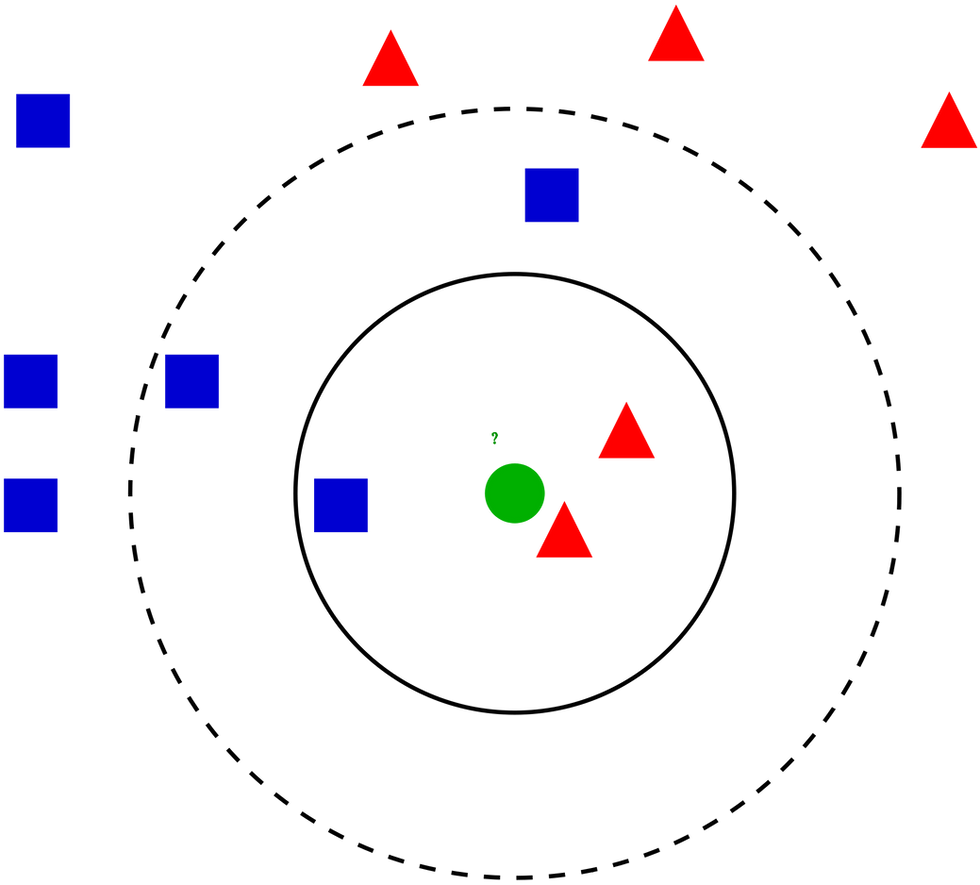
KNN: K Nearest Neighbor works by finding the distance between selected object and it's distance from K nearest neighbor and return the class having maximum number of same type of neighbors. In the below Image we need to find the class of green dot it belongs to. So we calculate the distance between green dot with respect to all other objects. If K is 3 then the green dot would be classified as red since there are 2 red and 1 blue object having 3 Neighbors. But if we change the size of k as 5 then green will be classified as Blue since number of blue is 3 and number of red object is 2.
Code:
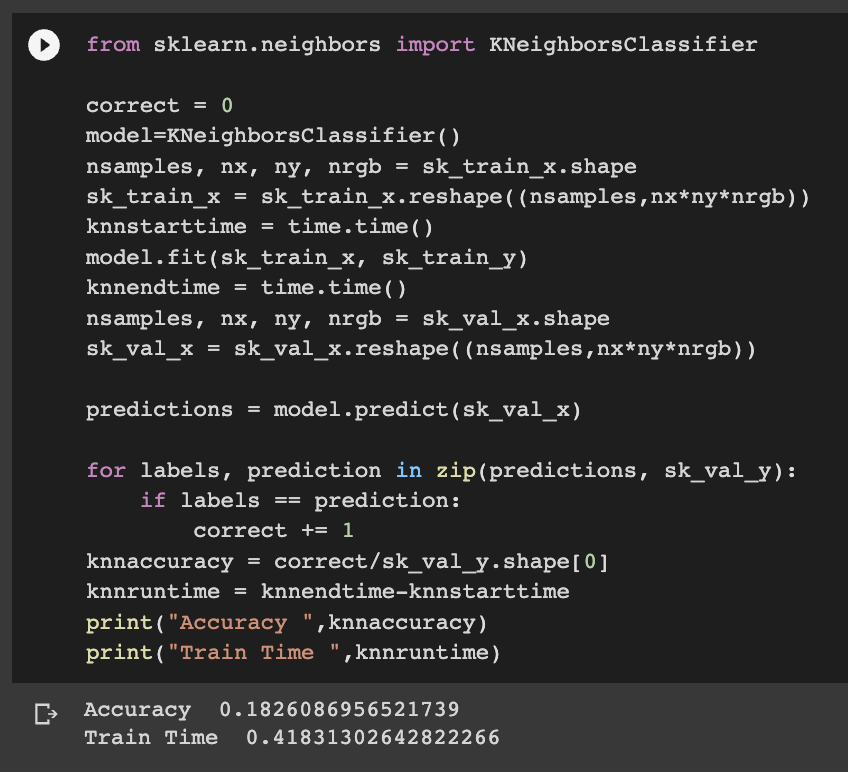
Accuracy: 18.26%
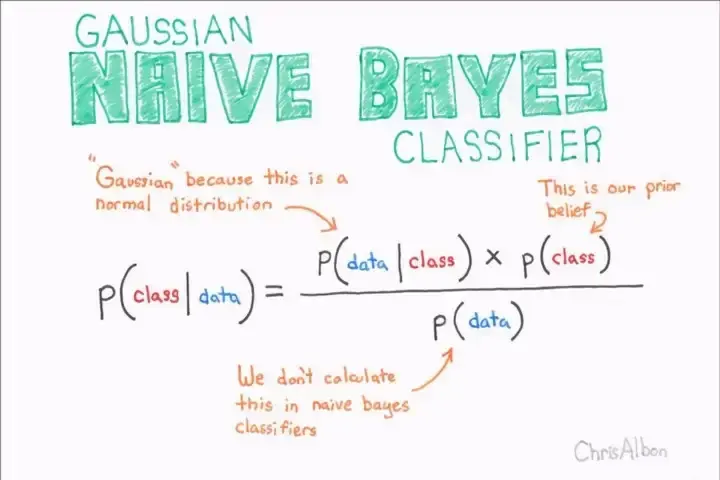
Gaussian Naive Bayes[14]: Here P(class|data) is conditional probability. The probability of getting class given data which is word in our case is true.
Here P(class|data) is conditional probability. The probability of getting class given data which is word in our case is true.
P(data|class) is the probability of getting data given the class is true. P(data ∩ class) this is also know as joint probability
P(class) is probability of getting class and P(data) is probability of getting data/word.
Advantage of Naive Bayes classifier:
For text data naive bayes can handle the missing data well and the text data may contain many missing words.
Code:
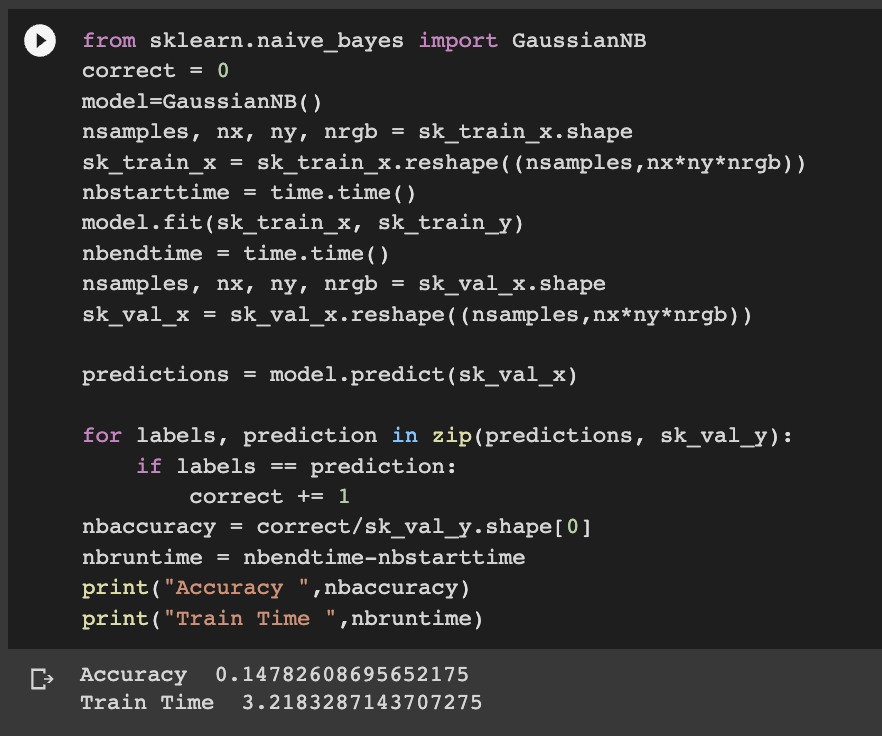
Accuracy: 14.78%
Decision Tree[11]: Decision tree is a flowchart-like tree structure, where each internal node denotes a condition on an attribute, each branch represents an outcome of the condition, and each leaf node (terminal node) holds a class label.
Code:
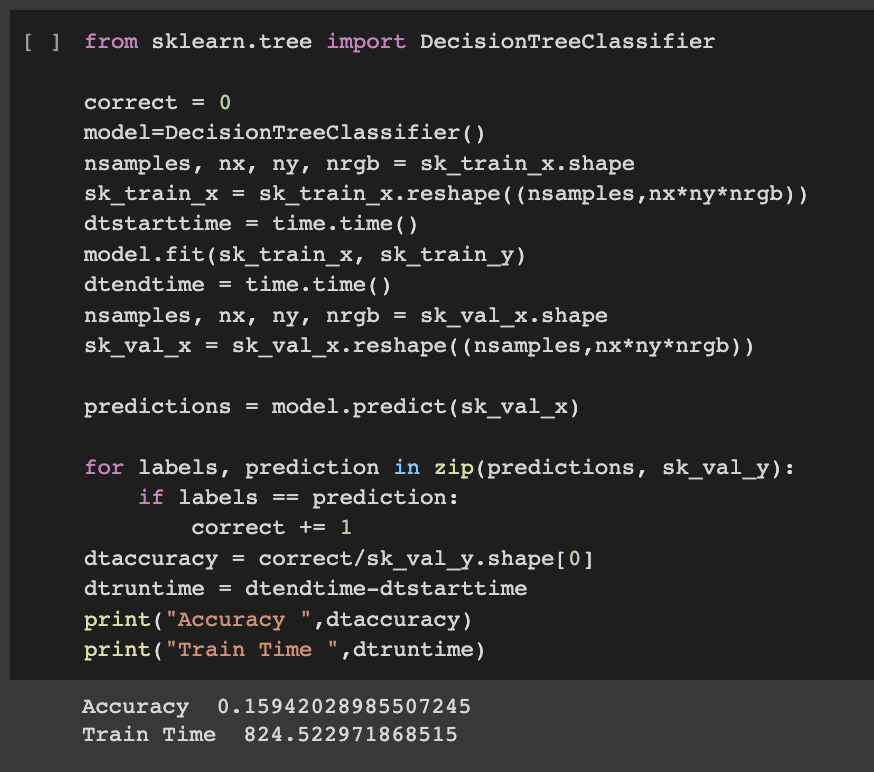
Accuracy: 15.94%
ML Model - Performance and Training Time Graph: The performace of KNN was highest in comparison to all other ML models. RandomForestClassifier has higher accuracy than decision tree. Overall accuracy lies between 15%-22%
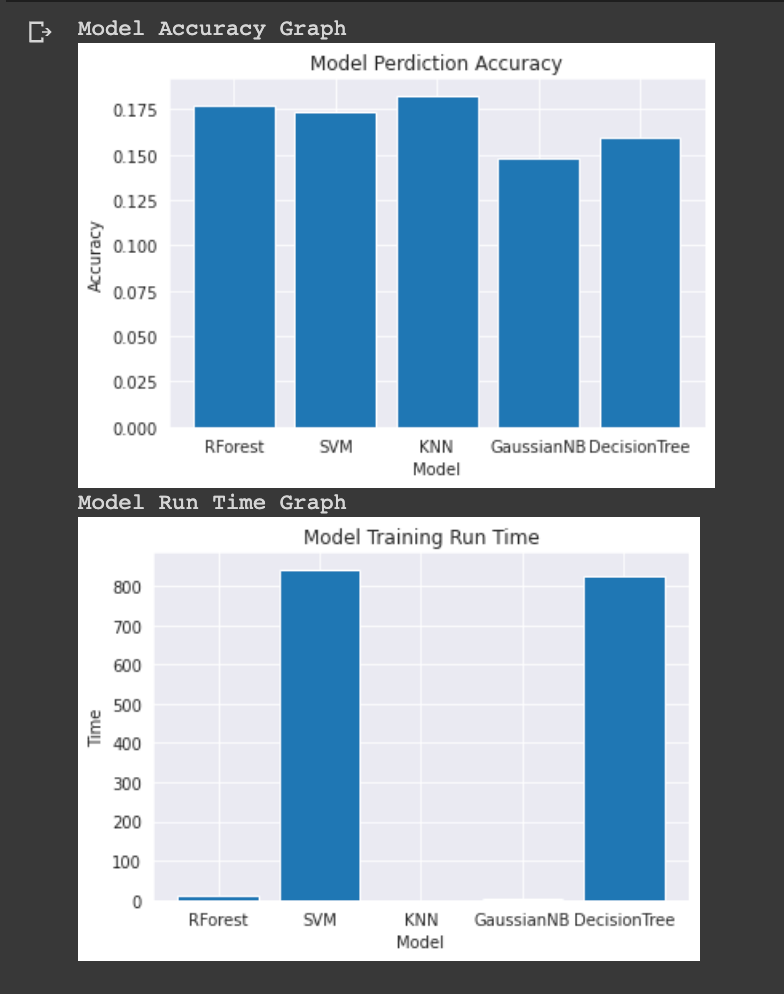
Comparison of performance all the models:
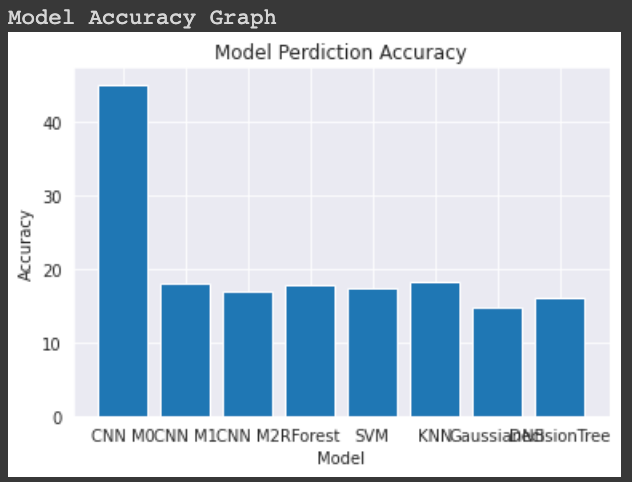
Comparison of training time all the models:
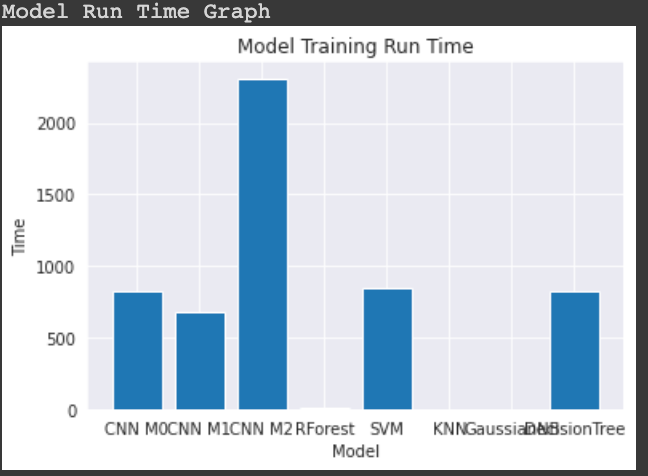
Experiments: The Accuracy for CNN model was initially 18% with epoch value of 5 and 10 and Hyper-parameters were AdaptiveAvgPool(3) and only 2 conv2d layer was used and input was set to 3, 6, 3 for first conv2d layer, optimizer as SGD. After 4-6 Iteration of tuning the hyper parameter the accuracy achieved was 45% with Model 0 with parameters AdaptiveAvgPool(6) and optimizer as ADAM and learning rate 0.001 with reLU as activation function. Graph for these experiment are in Training Model section above. Performed data augmentation and its impact on the performance of models.
For Machine learning models the parameters were changed from default but the performance was not very good. The experiments having best performance has their parameters defined as explained in the above section. Comparison of performance of CNN model and ML model and their training time.
Observation: The performance of CNN model 0 was better having accuracy of 45% after tuning the hyper parameters while all other models Random Forest, SVM, KNN, Gaussian NB, Decision Tree had accuracy of 15%-22%. The training time of CNN models are comparatively high then other models.
Few Experiment Results
Augmentation Iteration 0 Image Augmentation parameters [Resize(size=(300, 300), interpolation=bilinear, max_size=None, antialias=None), ToTensor()]
Augmentation Iteration 1 Image Augmentation parameters [Resize(size=(300, 300), interpolation=bilinear, max_size=None, antialias=None), GaussianBlur(kernel_size=(1, 1), sigma=(0.1, 0.5)), RandomRotation(degrees=[-5.0, 5.0], interpolation=nearest, expand=False, fill=0), RandomHorizontalFlip(p=0.5), ToTensor()]

Overfitting : CNN Model 1 had issue of overfitting where we can see that it's similar to model 0 but doesn't perform better than model 0 as we have increased the number of conv2d layer for more feature extraction but overall performance is not good.
Challenges and Resolution: The size of dataset was approximately 1GB and loading data took time. I have used only 512 size images of all the classes. Since the number of images were less around 300 images for each classes, I have used data augmentation to mitigate this issue. Google Colab crashed multiple time which lead to deletion of runtime data and i had to run the CNN models and ML models in two different runtime. Lost many iteration data due to crash. To plot the graph for both cnn and ml model i had to print the values and use that later to plot the graph due to runtime crash. Few png images were incompatible while loading the data so i had to remove those images in image preprocessing stage.
I tried using GradientBoostingClassifier algorithm with n_estimators as 200 but the model took more than 6 hours to run on google colab and finally it crashed. I changed to 10 for estimators but still it was not helpful it took more than 3 hours to get the output but that result I lost due to runtime restart.
Contribution:
Created custom function to run the models on different parameters like optimizer learning rate, data augmentationlist.
Created graph for class wise accuracy for all 3 CNN models.
Created models different layers to check the accuracy of each model.
Augmentation of image dataset and testing models accuracy against each dataset.
Created bar chart to visualize the different models accuracy and training runtime.
Performed experiments on sklearn models for all the 5 classifiers to get better performance
Comparison of performance and training time of all 8 models
Reference :
https://discuss.pytorch.org/t/how-to-split-dataset-into-test-and-validation-sets/33987/4
https://www.programcreek.com/python/example/92668/torch.optim.SGD
https://pytorch.org/tutorials/beginner/basics/data_tutorial.html
https://pytorch.org/vision/stable/transforms.html
https://www.geeksforgeeks.org/random-forest-classifier-using-scikit-learn/
https://medium.com/swlh/fully-connected-vs-convolutional-neural-networks-813ca7bc6ee5
https://www.analyticsvidhya.com/blog/2022/01/image-classification-using-machine-learning/
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.ensemble


Comments