Naive Bayes Classifier
- NIRAJ KUMAR
- Nov 14, 2022
- 3 min read

Problem Statement: To build Naive Bayes Classifier for Ford sentence classification Dataset
which text data categorized into 6 different Types : Responsibilty, Requirement, Skill,Softskill, Education, Experience
Introduction: Bayes Theorem[9]
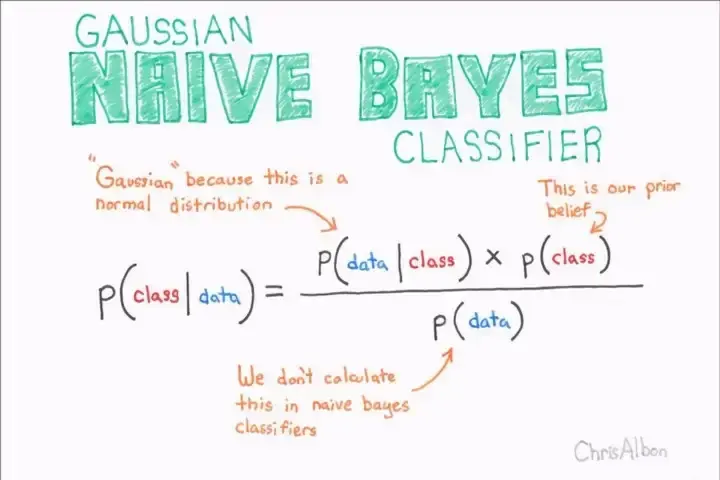
Here P(class|data) is conditional probability. The probability of getting class given data which is word in our case is true.
P(data|class) is the probability of getting data given the class is true. P(data ∩ class) this is also know as joint probability
P(class) is probability of getting class and P(data) is probability of getting data/word.
what is naive in naive bayes theorem?
The assumption that all the events are independent of each other and the probability of happening of one event is independent of other event which makes it naive.
Advantage of Naive Bayes classifier:
For text data naive bayes can handle the missing data well and the text data may contain many missing words.
How to handle missing data?
Using Laplace Smoothing [8] - when we have alpha value > 0 then it helps to avoid the probability of missing word to become 0. If we increase the alpha value to 0.001 it will increase the probability of that event to slightly but not zero.

Here alpha represents the smoothing parameter,
k : number of features in data
N : number of words|class
Dataset:
Importing dataset : I have upload the ford sentence dataset to my google drive and mounted the google drive to my google colab.

Checking for Null and NaN values in dataset

Removing Nan and Null Values from dataset and printing the dataset

Removing stop words except "the" from New_sentence and storing it in processed column[1]

Merge data into single dataset and creating training, development and test dataset using split of 0.8,0.1,0.1

create vocablist and a dictionary having key as word and value as the number of times the word appear.

Dictionary with word as key and occurrence as values

Find the positive review: I have used positive words from lexicon sentiment and calculated the positive and negative word present in the dataset. I have considered value 1 as positive sentiment and 0 as negative sentiment

Calculating the probability

P["the"] = number of sentence containing 'the'/num of all the sentence
Conditional Probability : P(the|positive)
functions for finding probability and conditional probability with smoothing parameter


Get Top 10 words in different dataset each type and calculate the probability and conditional probability for smoothing value 0.1


Derive Top 10 words and predict their class using naive bayes classifier for different dataset

Model accuracy
calculate accuracy:


Words and their predicted accuracy and models
final accuracy on development and test dataset
Development dataset result:
Test dataset result :

Probability and conditional probability of top 10 test data

Challenges: Google colab fails multiple times while handling large data like creating vocablist. Converting the data into list of processed data after removing stop words made the iteration expensive in terms of number of loops and increased time complexity significantly causing my colab to crash multiple times. Multiple iteration for smoothing resulted in no change to the probability. Once training data resulted in same class as predicted class for all the data in the dataset using NBC.
Contribution:
Calculating the sentiment on the processed data using opinion lexicon after removing stop words.[1],[2]
Find all the top words based on their respective Types
Calculating probability and conditional probability of the | sentiment along with Top words in different dataset and its respective probabilities.
Calculating the accuracy and classes of top words in different dataset
Increasing the model accuracy from 9% to 39%
Used python dictionaries for easy access to data to reduce the time complexity which I have had increased due to use of list.
NoteBook:
Reference [1] : https://www.analyticsvidhya.com/blog/2021/12/different-methods-for-calculating-sentiment-score-of-text/ [2] : https://www.cs.uic.edu/~liub/FBS/sentiment-analysis.html [3] : https://www.geeksforgeeks.org/how-to-merge-multiple-csv-files-into-a-single-pandas-dataframe/ [4] : https://www.analyticsvidhya.com/blog/2017/09/naive-bayes-explained/? [5] : https://www.w3resource.com/python-exercises/dictionary/python-data-type-dictionary-exercise-1.php [6] : https://becominghuman.ai/naive-bayes-theorem-d8854a41ea08 [7] : https://machinelearningmastery.com/naive-bayes-classifier-scratch-python/ [8] : https://towardsdatascience.com/laplace-smoothing-in-na%C3%AFve-bayes-algorithm-9c237a8bdece



Comments